
 Friday, 23 May 2008
Friday, 23 May 2008One of the first tasks when mapping (or translating) Shlaer-Mellor information models to XML documents or Java code is to flatten subtype-supertype hierarchies. Obviously, XML does not support any kind of generalization. While Java only allows single inheritence and this facility may be required to implement the objects within the Java software architecture.
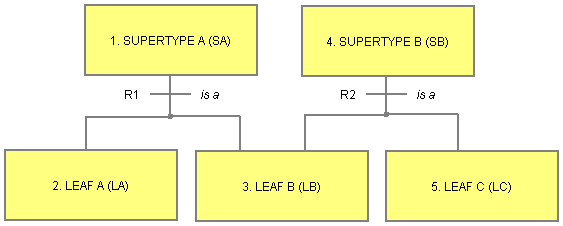
The diagram above shows leaf objects with single and multiple supertypes. The definition of a leaf object is any object which doesn't participate in a subtype-supertype relationship as a supertype object. This example is easily flattened into:
Leaf A containing Leaf A and Supertype ALeaf B containing Leaf B, Supertype A and Supertype BLeaf C containing Leaf C and Supertype B
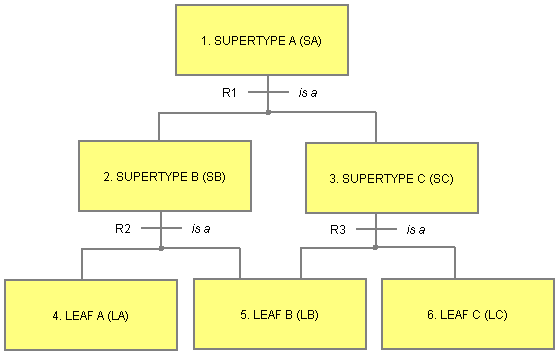
The diagram above shows an example of an improper subtype-supertype relationship. Leaf B is a subtype of Supertype B and Supertype C. However, the subtype-supertype relationship R1 specifies that all Supertype A objects are either Supertype B or Supertype C but not both. Executable UML (the UML version of Shlaer-Mellor) explicitly labels these relationships as disjoint to emphasis the point. C++ allows multiple inheritence with common base classes but Shlaer-Mellor OOA does not.
The other form of improper subtype-supertype relationship is where a subtype ends up being a supertype of itself via a circular chain of subtype-supertype navigations.
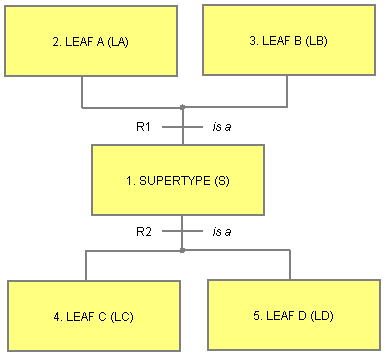
The diagram above shows an example of compound subtype-supertype relationships where Supertype is a Leaf A or Leaf B and a Leaf C or Leaf D. To flatten this example requires the introduction of new compound leaf objects:
Leaf A/C containing Leaf A, Supertype and Leaf CLeaf A/D containing Leaf A, Supertype and Leaf DLeaf B/C containing Leaf B, Supertype and Leaf CLeaf B/D containing Leaf B, Supertype and Leaf DCompound subtypes may participate in other subtype-supertype relationships either as supertypes or subtypes leading to complex hierarchies. However, as long as there are no improper subtype-supertype relationships then these hierarchies can always be flattened into leaf and compound leaf objects.
The algorithm for flattening subtype-supertype hierarchies gave me a few headaches before I settled on a two pass strategy:
All flat elements contain at least one leaf object. A flat element containing multiple leaf objects represents a compound leaf object. A suitable name may need to be chosen for compound leaf objects since they aren't explicited defined in Shlaer-Mellor information models.
Flat elements can be easily mapped to XML elements as long as a suitable name for compound leaf objects can be determined. The XML attributes for the element are determined from the combined attributes of the flat element's set of component objects. All simple attributes except Arbitrary ID or Ordinal ID attributes are required. Mathematically dependent attributes may be useful but are not absolutely required. All referential attributes used solely to formalize subtype-supertype relationships can be ignored. Referential attributes used to formalize containment relationships can also be ignored. Only referential attributes used to formalize referential relationships need to be considered. All polymorphic attributes can be ignored since the true attributes must also be present. Attribute names may need to be qualified when they are mapped to XML attribute names. I will leave the discussion of containment and referential relationships within XML documents to another day.