
 Wednesday, 27 August 2008
Wednesday, 27 August 2008
Names within OOA10's OOA of OOA are represented using a single attribute with a data type of Name. However, names are more complicated than they first appear. Names need to be formatted into numerous formats across various diagrams and generated work products. Letter case will often change during this formatting, as will the separator text before, between and after the words which compose each name. However, even though a name may have many formatted representations, there needs to be an underlying name for determining uniqueness within the context of what is being named. This underlying name needs to be case-insensitive and independent of particular separator text so that uniqueness is maintained in the many formatted representations of each name. A Naming service domain has been created to formalize names and name formats.
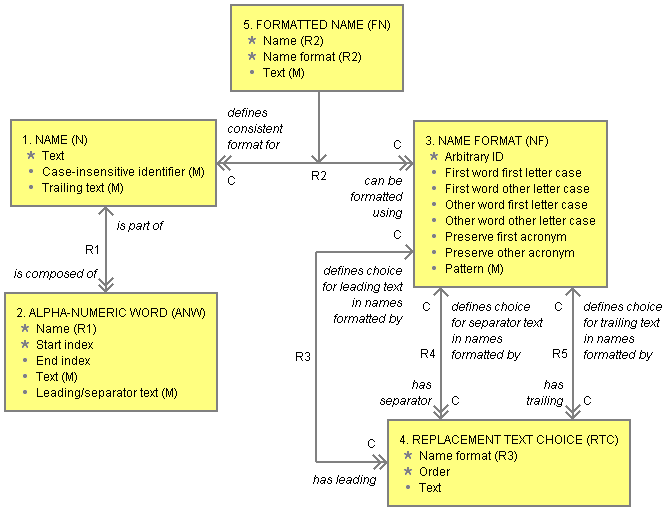
The object information model for Naming is given below:
The equivalent class diagram for Naming can also be shown since OOA Tool now supports Executable UML notation:
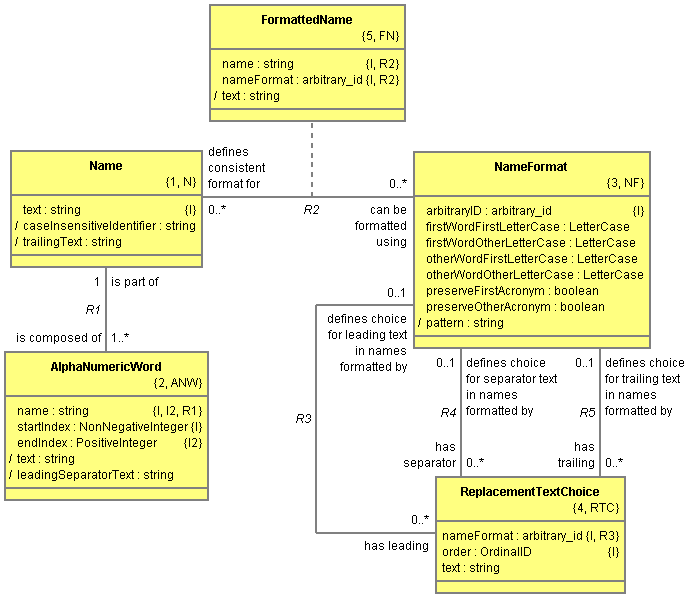
In the above model, names retain their original Unicode text representation. This representation is converted into a case-insensitive identifier by stripping out all non alpha-numeric characters, including characters such as underscore which are normally allowed within identifiers, and converting the remaining characters into lower case. Since we don't want empty identifiers, all names must include at least one letter. We also don't want any identifiers starting with a digit, so any leading digits are ignored when determining this identifier. The case-insensitive identifier is only unique within certain contexts which is why it is not an identifying attribute in the model above.
Each name is decomposed into one or more alpha-numeric words to simplify formatting. Each word is either all letters or all digits. In the model above, alpha-numeric words contain start and end indexes for the word's text within the original text representation. This also allows us to determine any separating text that precedes the word. This appears to break the normal Shlaer-Mellor rule that attribute values are atomic. However, data values in OOA10 are write atomic but not necessarily read atomic.
Name formats allow letter case to be specified for first letter and secondary letters of first word and secondary words (other replaces secondary in the model above). Name formats also allow acronyms to be preserved even when embedded within CamelCase names.
Name formats are represented using a pattern, the syntax of which is given below:
pattern := textChoices // Leading text choices
( 'A' | 'a' | '?' ) // First word first letter case
( 'A' | 'a' | '?' ) // First word other letter case
textChoices // Separating text choices
( 'A' | 'a' | '?' ) // Other word first letter case
( 'A' | 'a' | '?' ) // Other word other letter case
textChoices // Trailing text choices
[ 't' | 'f' ] // Preserve first acronym case
[ 't' | 'f' ] // Preserve other acronym case
textChoices := { '(' { ! ')' $anyCharacter }* ')'
| '[' { ! ']' $anyCharacter }* ']' }*
Letter case is determined by using 'A' for upper case, 'a' for lower case and '?' for any case. Whether OOA Tool's Archetype Language will allow the pattern syntax defined above to be used directly within substitution expressions to control the formatting of text.
Acronyms may span multiple alpha-numeric words since technical acronyms often include digits (e.g. J2SE). However, we need to watch out for 'A' and 'I' which are valid words in their own right. A syntax which summarises the rules for matching acronyms is given below:
acronym := acronymStart { acronymPart }*
acronymStart := $upperCaseLetter { $upperCaseLetter }+
| ! 'A' ! 'I' $upperCaseLetter
| 'A' !! $digit | 'I' !! $digit
acronymPart := { $upperCaseLetter }+ | { $digit }+
The main name formats used in OOA Tool are listed below:
Name Format Pattern All Caps Title Case ()AA( )(-)(/)AA()Title Case ()Aa( )(-)(/)Aa()ttUpper Sentence Case ()Aa( )(-)(/)aa()ttLower Sentence Case ()aa( )(-)(/)aa()ttAll Caps Underscore Case ()AA(_)AA()Title Underscore Case ()Aa(_)Aa()ttUpper Underscore Case ()Aa(_)aa()ttLower Underscore Case ()aa(_)aa()ttAll Caps Camel Case1 ()AA()(_)AA()Upper Camel Case2 ()Aa()(_)Aa()ttLower Camel Case2 ()aa()(_)Aa()ft
- Not parsable unless underscore separators used.
- Parsable as long as two acronyms don't appear next to each other.
The table below identifies where the above name formats are used within OOA Tool's Shlaer-Mellor and Executable UML diagrams:
Where Shlaer-Mellor Executable UML Domain Chart domain names Title Case Title Case Domain Chart subsystem names Upper Sentence Case N/A Domain Chart prominent object names Lower Sentence Case N/A SRM/SCM/SAM1 subsystem names Title Case Title Case SRM/SCM/SAM1 subsystem prefix letters All Caps Camel Case All Caps Camel Case
Upper Camel CaseSRM/SCM/SAM1 prominent object names Lower Sentence Case N/A OIM2 subsystem names Title Case Upper Camel Case OIM2 object names All Caps Title Case Upper Camel Case OIM2 object key letters All Caps Camel Case All Caps Camel Case
Upper Camel CaseOIM2 attribute names Upper Sentence Case Lower Camel Case OIM2 data type names N/A Upper Camel Case3 OCM4 state model/terminator names Title Case Title Case OCM4 event meanings Upper Sentence Case Lower Camel Case OAM5 state model/terminator names Title Case Title Case OAM5 accessor meanings Upper Sentence Case Lower Camel Case STD6 state names Upper Sentence Case Title Case STD6 event meanings Upper Sentence Case Lower Camel Case STD6 supplemental data item names Lower Sentence Case Lower Camel Case ADFD7 names TBD N/A Thread of Control Chart8 names TBD TBD Use Case Diagram names N/A TBD
- Subsystem Relationship Model/Subsystem Communication Model/Subsystem Access Model.
- Object Information Model or Class Diagram in Executable UML.
- User data type names are formatted in Upper Camel Case while core data type names are formatted in lower case.
- Object Communication Model or Collaboration DiagramUML1/Communication DiagramUML2 in Executable UML.
- Object Access Model.
- State Transition Diagram or Statechart DiagramUML1/State Machine DiagramUML2 in Executable UML.
- Action Data Flow Diagram.
- Thread of Control Chart or Sequence Diagram in Executable UML.
Name formats within Action Language and Archetype Language code are determined by whoever writes the code. Since uniqueness of names is determined by the case-insensitive alpha-numeric identifier associated with each name, name formats can be mixed within code. However, the following name formats are recommended:
Whichever name formats are used in your code, they should be used consistently.
Where Shlaer-Mellor Executable UML Object/Class names Title Underscore Case Upper Camel Case Attribute names Upper Underscore Case Lower Camel Case Supplemental data item/parameter/variable names Lower Underscore Case Lower Camel Case